Introduction
The goal of this project was to web scrape the Yellow Pages website to extract business names and email addresses to create a dataset. This idea came to me as I was working in preconstruction for Winter Construction. There was an invitation to bid system that has a list of business and email addresses of companies that we invite to bid on project. The system mostly only had companies in the Atlanta area. We were bidding on a project in Greenville South Carolina, and I thought a good way to get emails from construction companies there would be to create my own list of subcontractors from the Greenville area using this web scraping technique. This method can be used for any business on the yellow pages. For this project, I decided to look at moving companies in the New York area.
To begin the project, all the libraries that were needed were imported. Beautiful Soup was the web scaping technology that was used for the project.

After everything needed was imported, I created a function that would parse the html of the web page to get the information I needed. The goal was to extract business names and their corresponding email addresses. To determine how to get this information, I went to the web page I was scraping and right clicked and selected “inspect” to pull up the underlying HTML code. Starting on the first page, I got scrapped to get the link that takes you to that specific business’s web page in Yellow Pages. This is shown in the link_ variable below. Once on a business’s personal page, the business name and email address were then retrieved as shown in the name and emaill variables. Some of the businesses on the website do not include an email address, this was considered in the if statement in the for loop. Without taking this into account, the code would output an error. Print was used to see the program actively working and then the data was transferred to the email list and business name list.
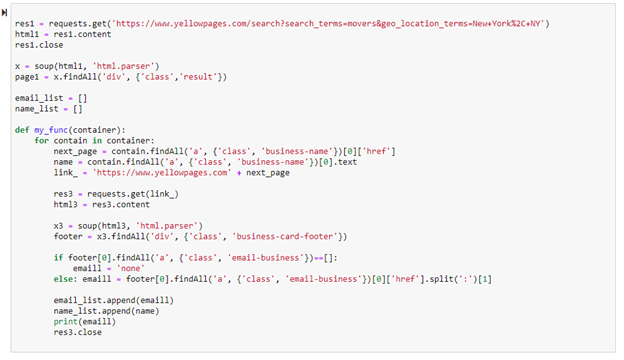
This image shows the output that is continuously being shown as the code parses each email address. This was included to make sure the code is running properly. Notice the “none” value in the list showing that this company did not have their email address in the website.
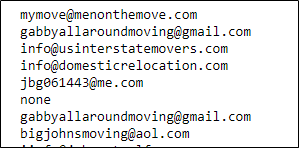
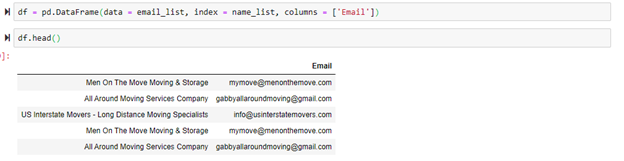
Here is the head of the final data frame that was created from parsing the fist page.
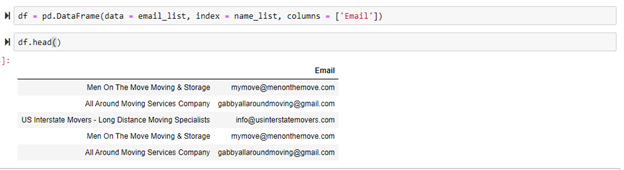
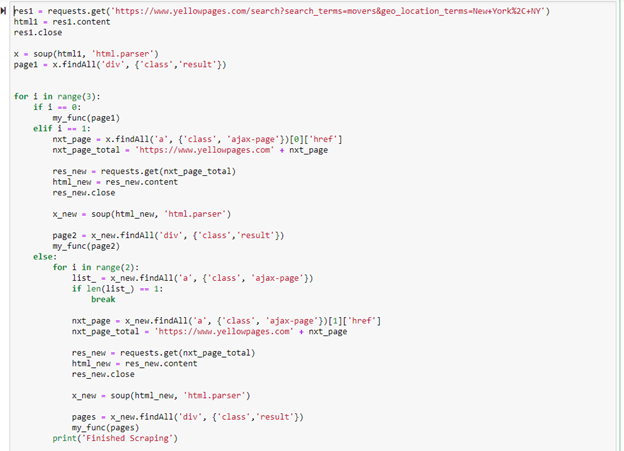
After the first scrape was successfully completed. I realized that this code would only scrape one page on the website. To truly automate extracting a lot of email, the code needed to jump to the next page of companies after the first page of company’s data were fully extracted. Starting on the original page, I inspected the next button and used that information to extract the link that takes you to the next page of companies. Then tested it to make sure it worked as shown below.
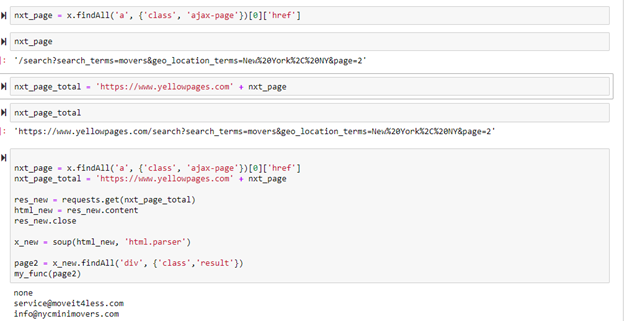
Below shows the code used to scrape the rest of the web pages. The range in the for loop can be changed depending on how many pages are desired to be scraped for data. Notice in this code snip how the value for the variable “nxt_page” has a [1] to the left of [‘href’]. In the previous code snip, this 1 was shown as a 0. This is because the first page in the sequence of webpages had the link to the next page located at a slightly different location than the rest of the web pages.
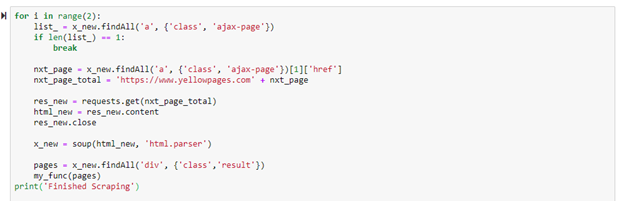
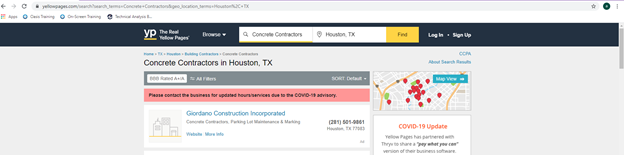
After trial and error, the final code for scraping the Yellow pages can be seen below. This is using the “my_func” function that was originally created. The variable “res1” can be replaced with a link to any initial search in the web pages. For example, see the image of the Yellow Pages website. This search is for concrete contractors in Houston, Texas. This URL link can be placed in the res1 variable, and it will still work just the same. The other option to change in this code is the range length in the for loop. The first two statements in the if and elif portion cover the first two pages of web scraping. The range value can be changed to scrape as many more pages past the first two pages that are desired. Range(2) tells the program to scrape three additional pages after the first two.
After all of the data has been scraped and added to lists, the lists can then be added onto the data frame as shown below.
Conclusion
Being able to extract data from any website on the internet is an extremely useful tool. This tool can be used to create machine learning data sets, lead generation, news and content monitoring, competitive market research, product and pricing intelligence, and much more. Successfully completing this project gave me the knowledge to successfully scrape data from any website on the internet. This project could be taken further in many ways. One would be creating a graphical user interface that allows a third-party user to web scrape the information themselves without knowledge of how to code. Another way would be to create a database connected to this system that collects and saves all the information as it is being scrapes.